In brief, this extended version enriches our framework as a full-stack, versatile solution for face vision security.

Key differences and new contributions of this extension compared to the FSFM (CVPR25) conference version:
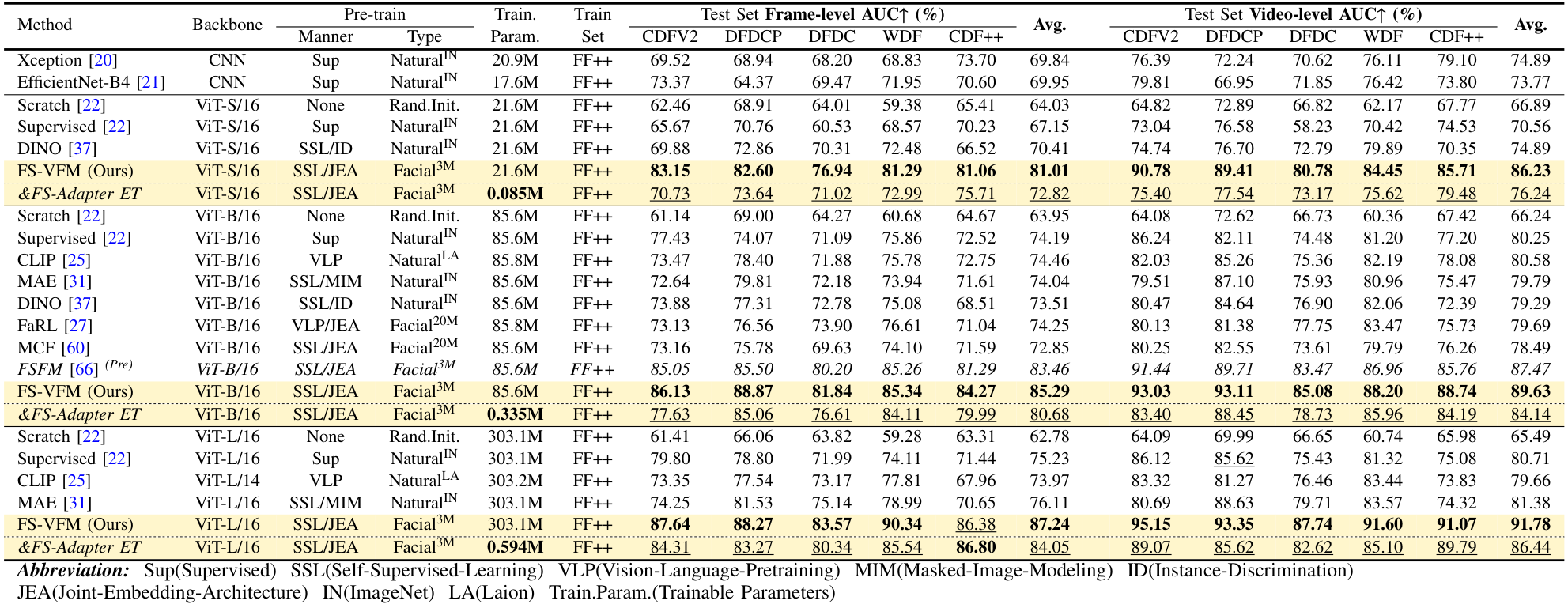
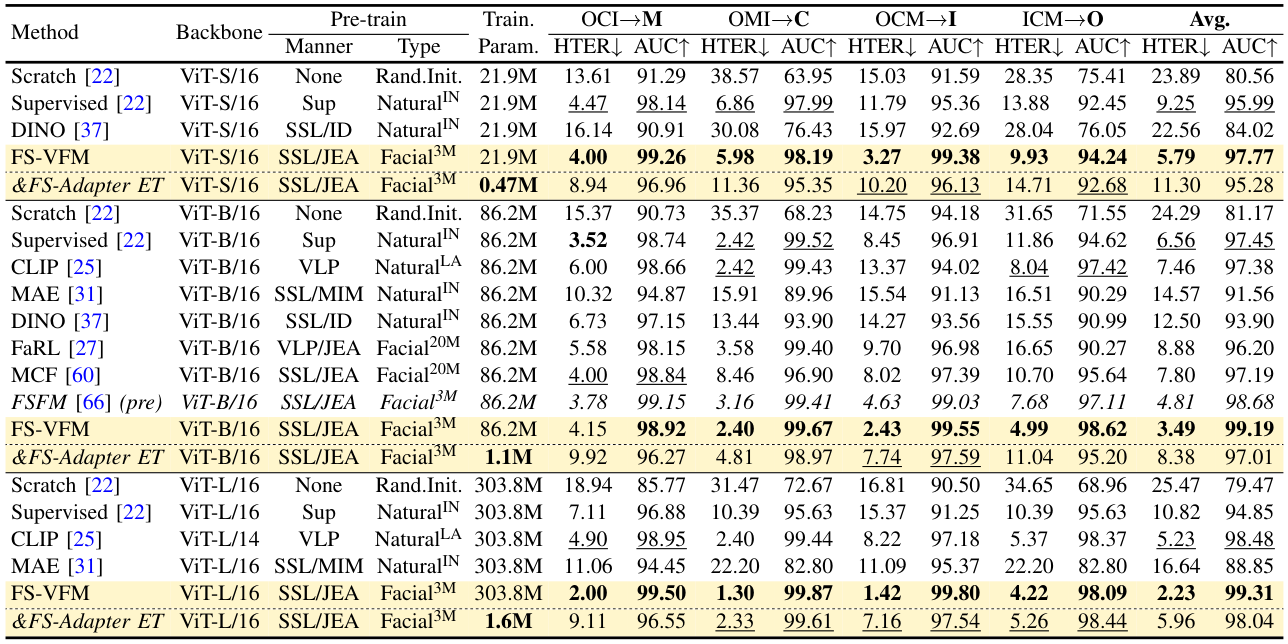
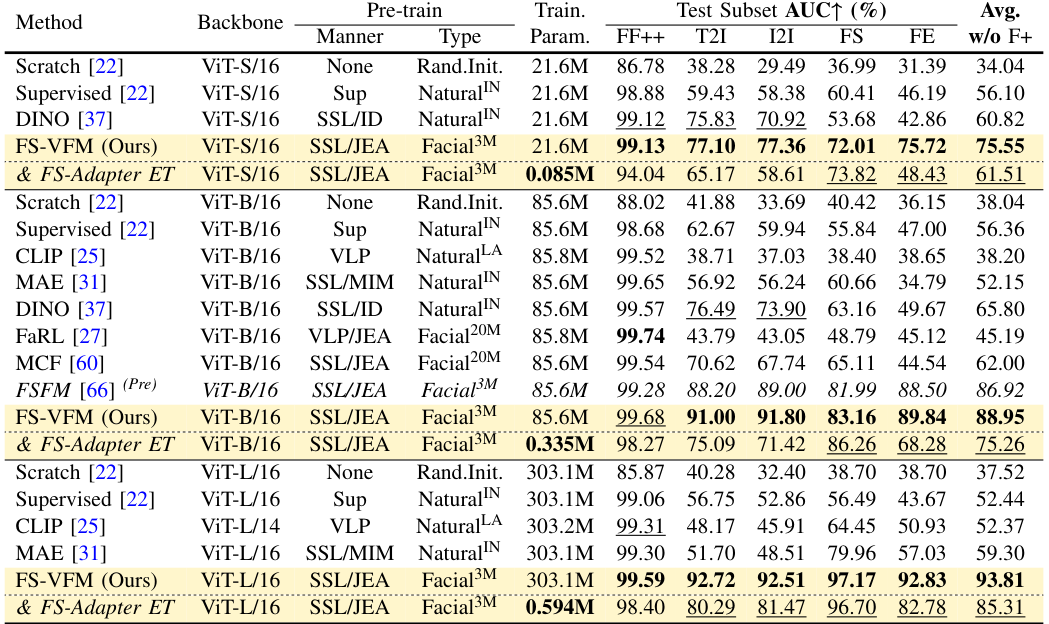
- Scalability We scale the model from a single ViT-B in the previous FSFM to a family of FS-VFM {ViT-S, ViT-B, ViT-L}, highlighting the effectiveness of our method across different model capacities and demonstrating consistent generalization gains across all face security tasks.
- Novel FS-Adapter We introduce FS-Adapter, a lightweight plug-and-play bottleneck module featuring novel real-anchor contrastive learning, which enables the efficient transfer of our FS-VFMs to downstream face security tasks while retaining superior generalization performance.
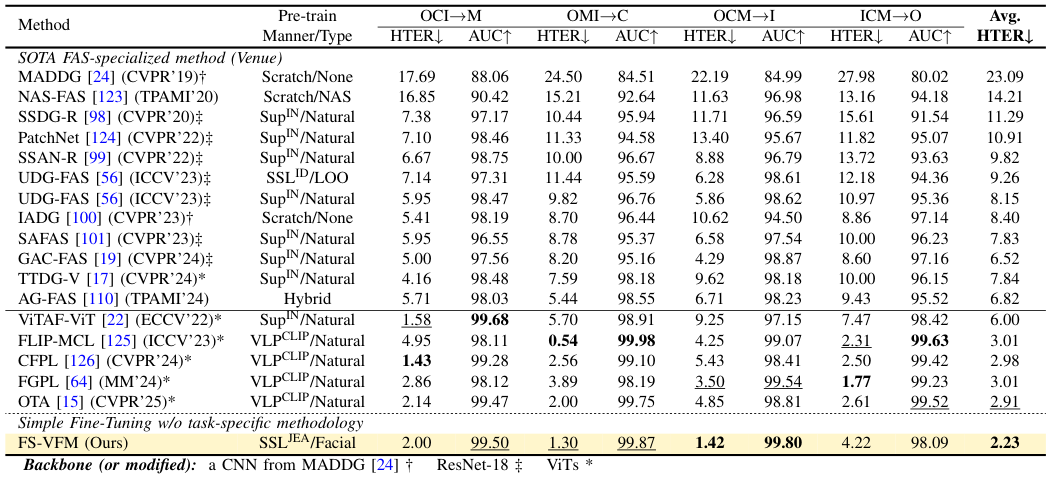
- Improved Generalization and Efficiency Simple fine-tuning of the FS-VFM ViT sets a new generalization baseline for deepfake detection, diffusion-generated face forensic, and face anti-spoofing, while FS-Adapter facilitates efficient adaptation to downstream face security tasks.
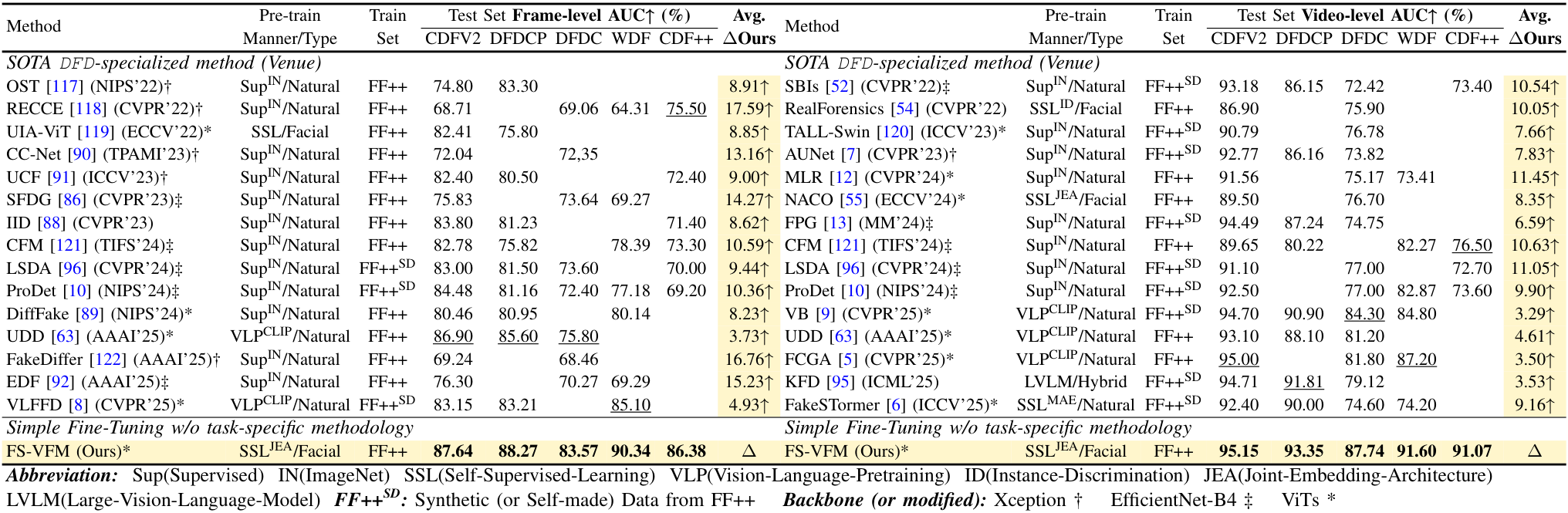
- Broader and Deeper Evaluation We benchmark FS-VFM against a wider range of vision foundation models spanning different pre-training domains, paradigms, and scales; we include a recent Celeb-DF++ dataset; we also update the SOTA task-specialized methods for comparisons.
- Deeper Analysis We provide new insights into our method, including model and data scaling, ablations, quantitative and qualitative analyses.