Overview
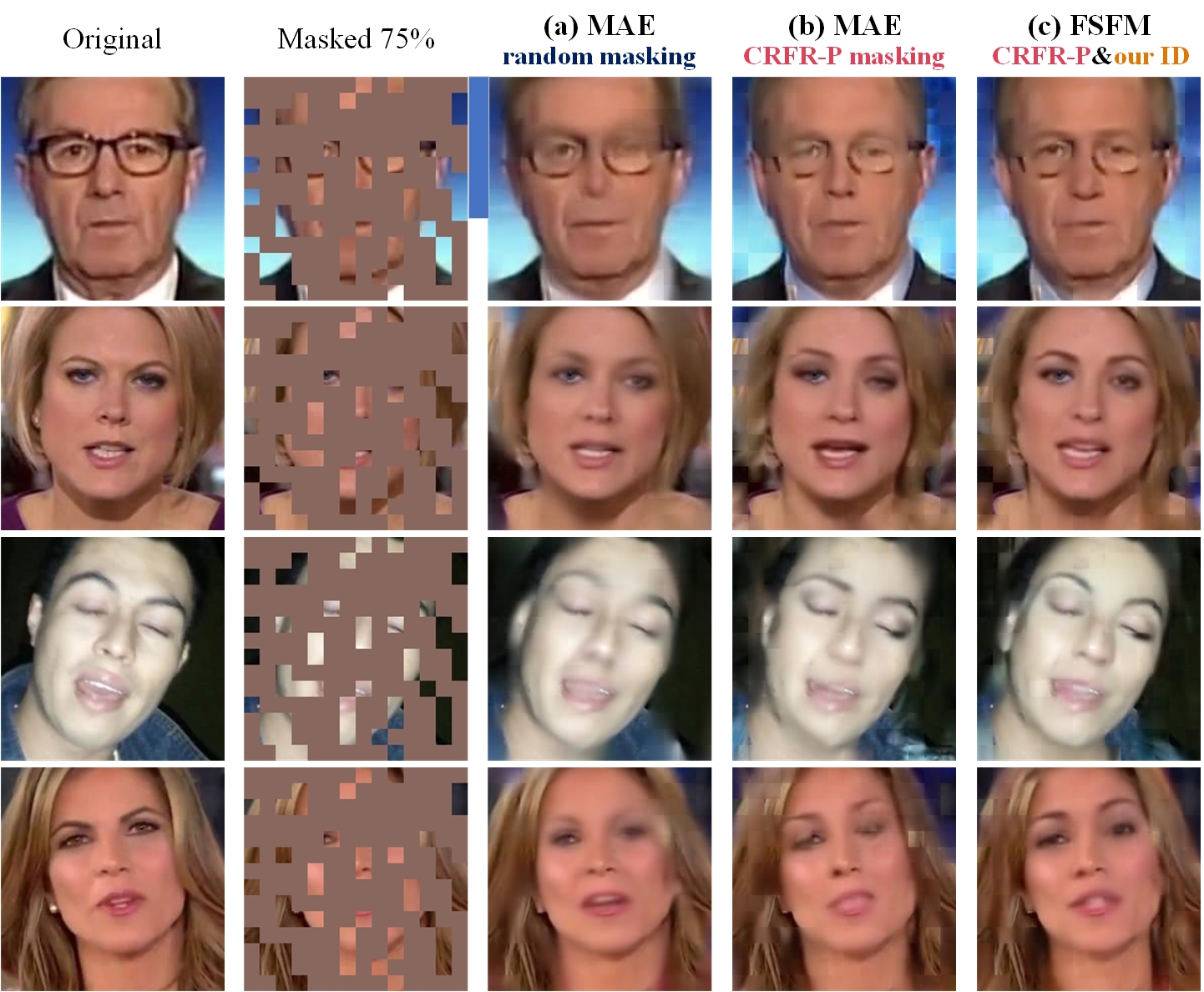
The self-supervised pretraining framework for learning fundamental representations of real faces (3C💣). Guided by the CRFR-P masking strategy, the masked image modeling (MIM) captures intra-region Consistency with \( \mathcal{L}_\mathit{rec}^\mathit{m} \) and enforces inter-region Coherency via \( \mathcal{L}_\mathit{rec}^\mathit{fr} \), while the instance discrimination (ID) collaborates to promote local-to-global Correspondence through \( \mathcal{L}_\mathit{sim} \). After pretraining, the online encoder \( E_\mathit{o} \) (a vanilla ViT) is applied to boost downstream face security tasks.
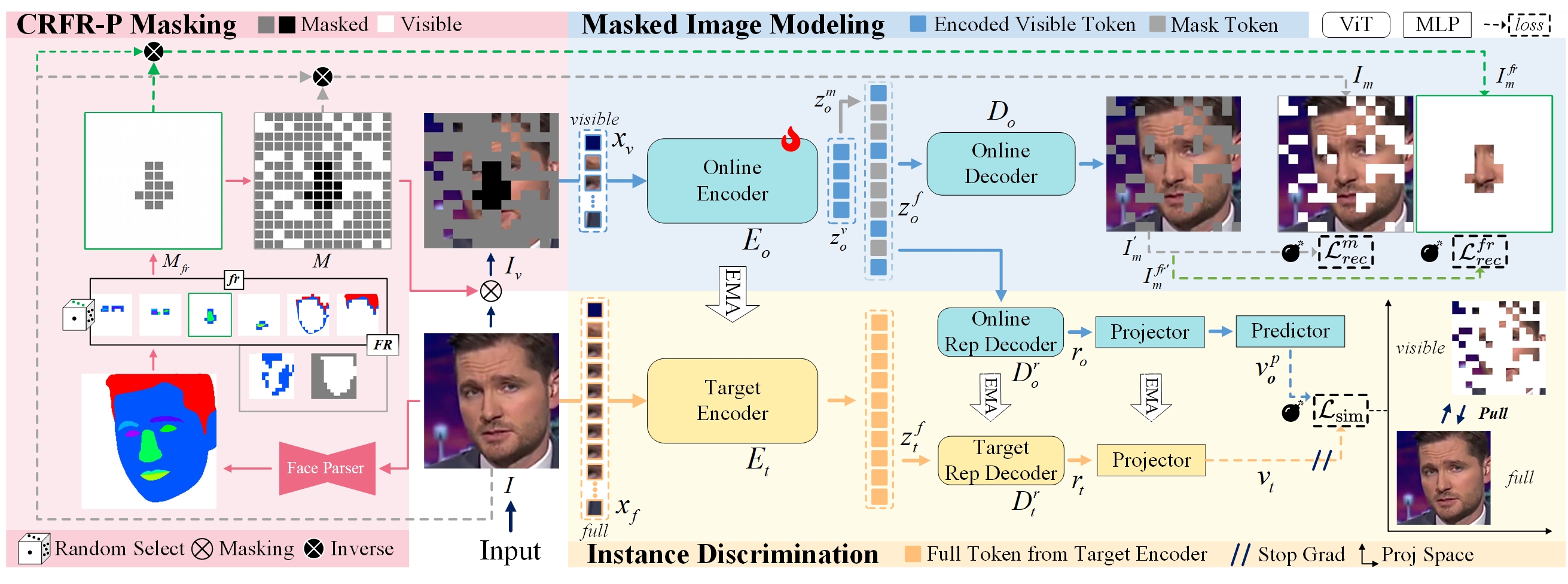
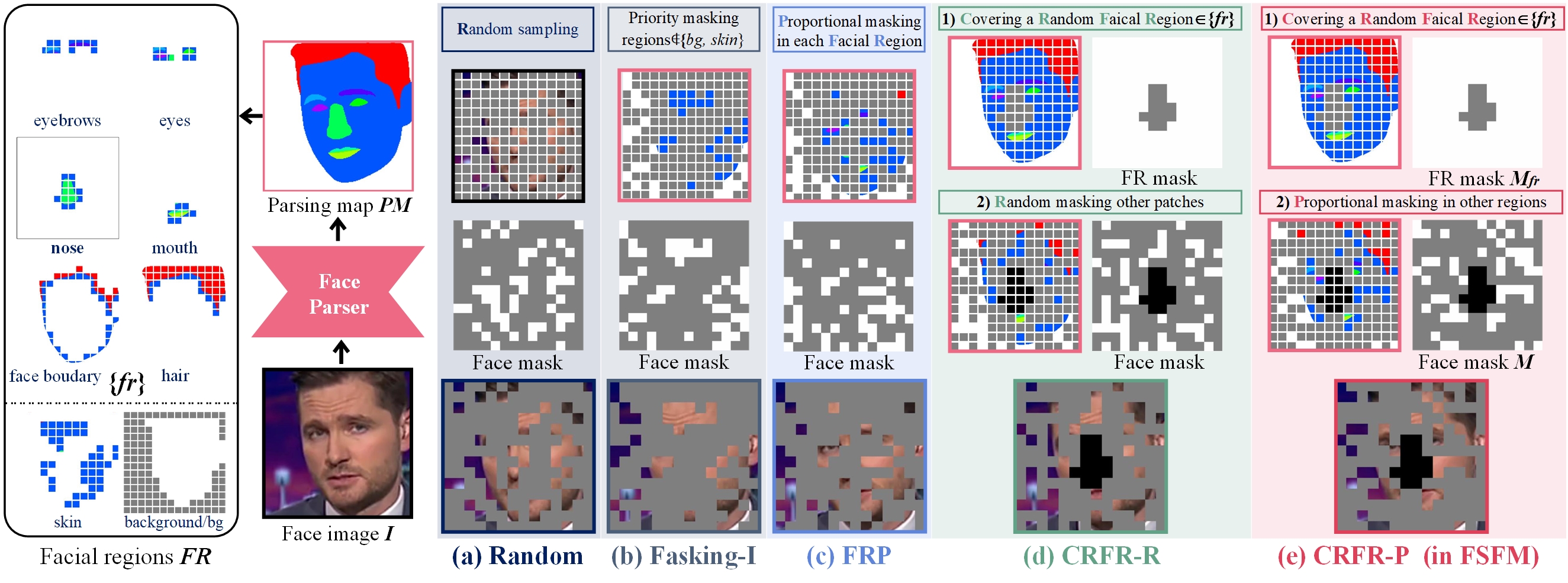
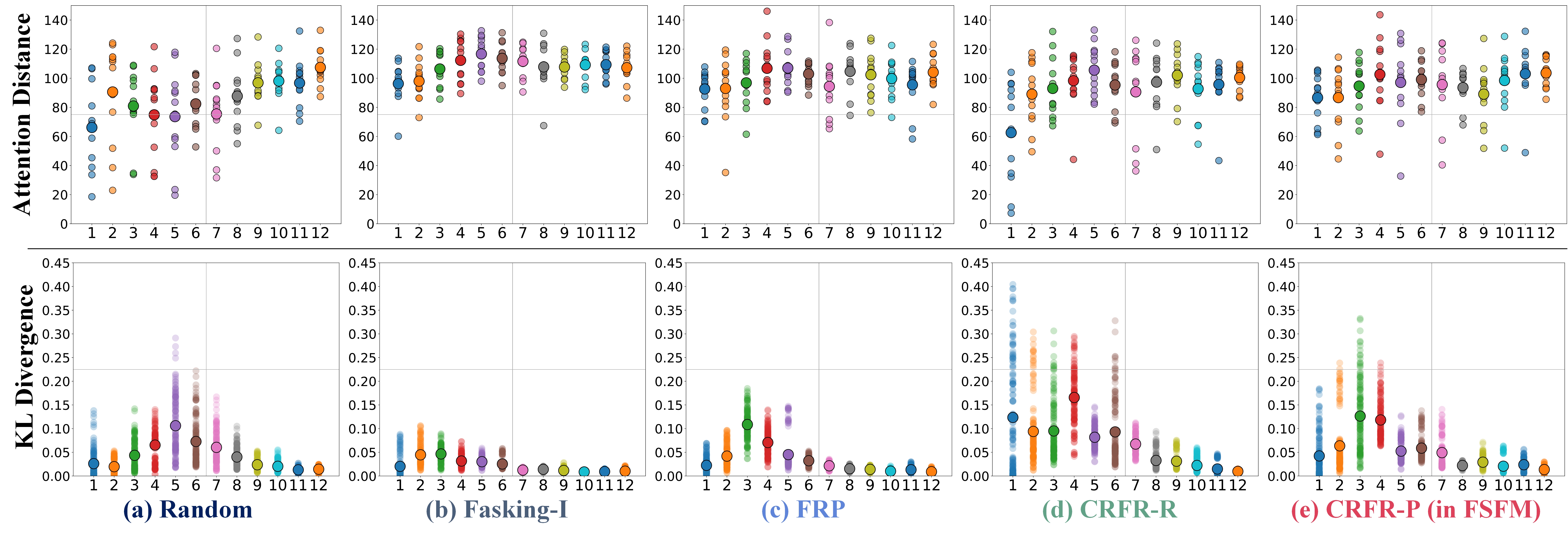
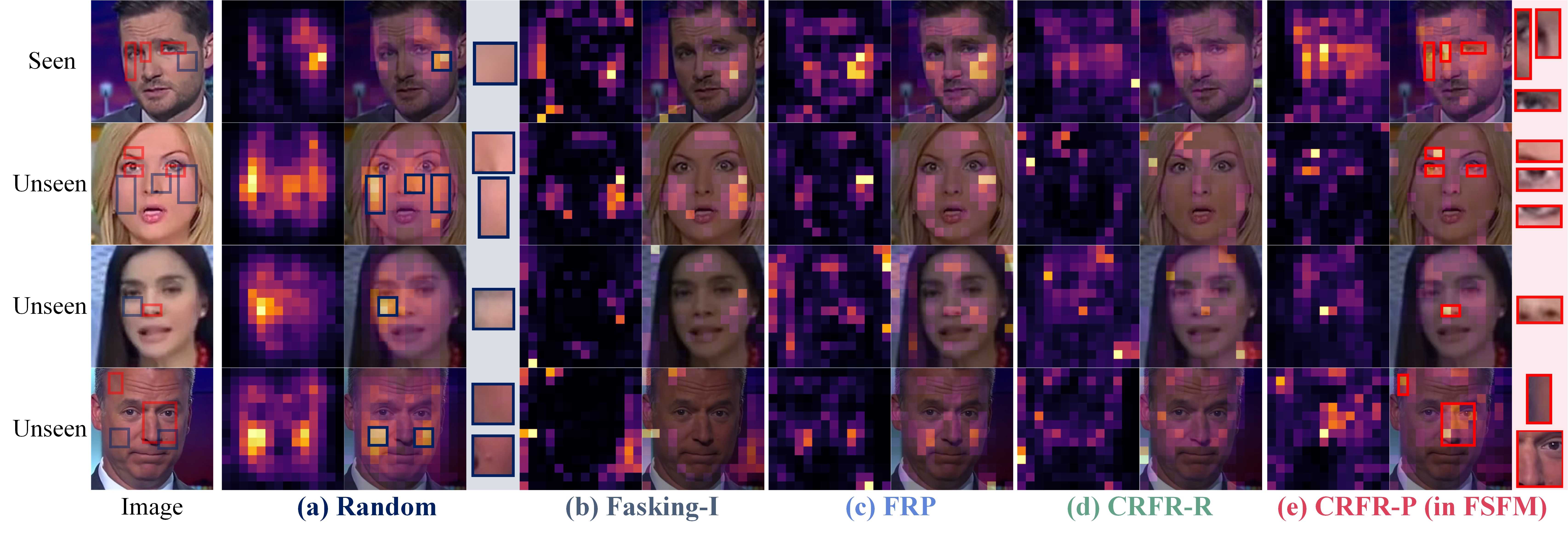
Given an input image \( I \), the CRFR-P strategy generates a facial region mask \( M_\mathit{fr} \) and an image mask \( M \). The MIM network, a masked autoencoder, reconstructs the masked face \( I_\mathit{m} \) from visible patches \( x_\mathit{v} \) (masked by \( M \)), with an emphasis on the fully masked region \( I_\mathit{m}^\mathit{fr} \) (specified by \( M_\mathit{fr} \)). The ID network maximizes the representation similarity between the masked online view and the unchanged target view of the same sample by projection upon a disentangled space structured by Siamese rep decoders.